Cascaded-ViT
Cascaded Chunk-FeedForward and Cascaded Group Attention Vision Transformer
Srivathsan Sivakumar, Faisal Z. Qureshi
Energy and Memory Efficient Vision Transformers
Cascaded-ViT (CViT) is a resource-efficient ViT, explicitly optimized for energy and memory consumption. The architecture uses Chunk-FFNs with a cascading nature to produce a family of light-weight, compute-efficient and high-speed vision transformers.
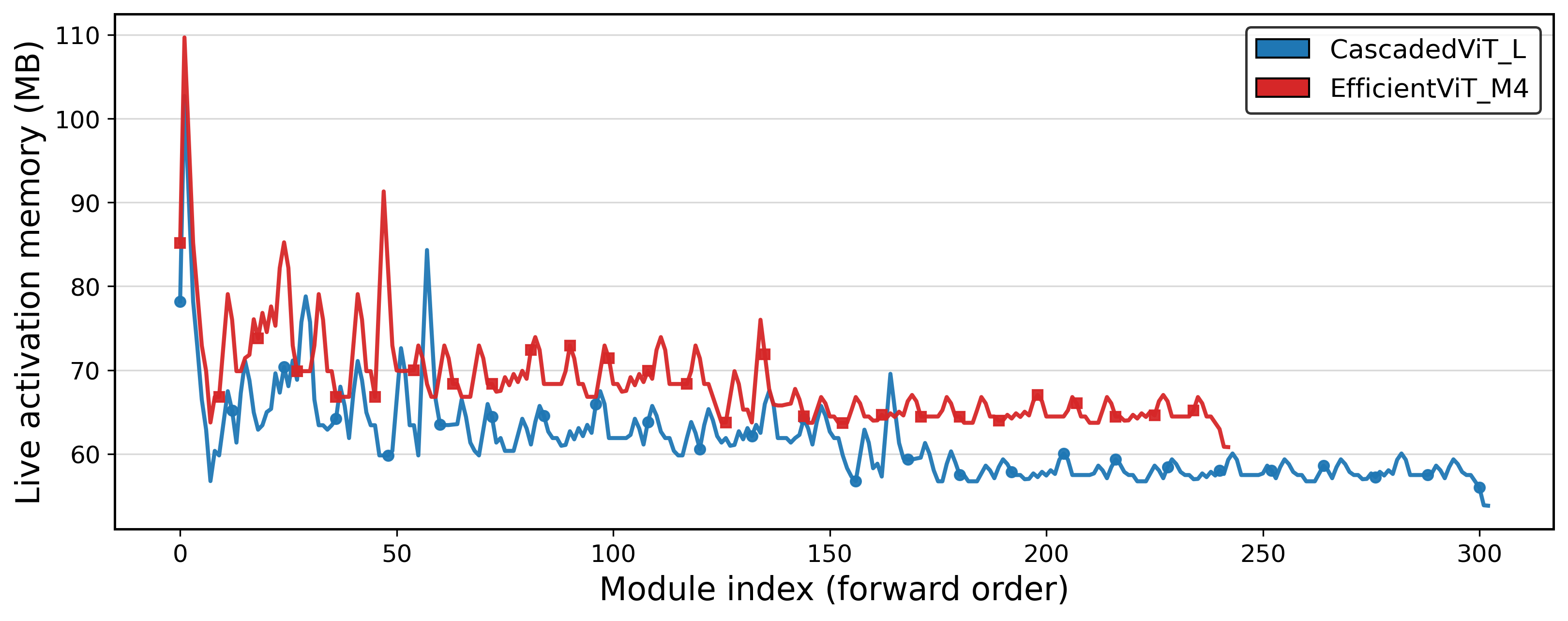
CViT achieves lower memory and energy consumption compared to size-equivalent EfficientViT while maintaining competitive accuracy on ImageNet
| Model | Accuracy (%) | Energy (mJ/Img) on M4 Pro |
Latency (ms/img) on iPhone 15 Pro |
|---|---|---|---|
| CascadedViT-L | 73.0 | 588±42 | 0.70 |
| EfficientViT-M4 | 74.3 | 620±45 | 0.79 |
The models are also deployable on AMD’s RyzenAI chips in addition to Apple devices.
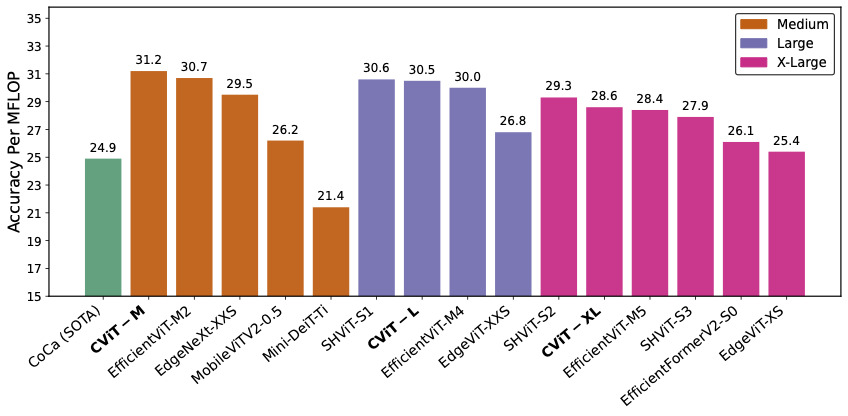
Accuracy Per Flop
Following Green AI principles, we defined a custom metric that quantifies accuracy gained per MFLOP. Experiments based on this metric show that CascadedViT achieve top-rank efficiency across all sizes.
Download our pretrained weights from our model zoo